新闻资讯
热点资讯
- 官方刘亚楼也认真严肃的示意-火星电竞·(CHINA)官方网站
- 火星电竞当日最高报价48.00元/公斤-火星电竞·(CHINA)官方网站
- 火星电竞·(CHINA)官方网站 从官方发布的海报可知-火星电竞·(CHINA)官方网站
- 火星电竞·(CHINA)官方网站企业开发了无东谈主机处理平台和数据处理平台-火星电竞·(CHINA)官方网站
- 火星电竞游戏第一品牌也对行业自己冷落了更高的条目-火星电竞·(CHINA)官方网站
- 火星电竞游戏第一品牌原因是在决定刑事职守握有的安分基金股权时-火星电竞·(CHINA)官方网站
- 官方跟着“以旧换新”计谋落地-火星电竞·(CHINA)官方网站
- 火星电竞游戏第一品牌辅导:TipRanks为平定第三方-火星电竞·(CHINA)官方网站
- 官方匡助武里南联三度问鼎泰超-火星电竞·(CHINA)官方网站
- 火星电竞接下来是“投其所好”-火星电竞·(CHINA)官方网站
- 发布日期:2025-06-11 07:43 点击次数:156

 智东西
智东西
智东西6月10日报谈,近日,大模子开源圈迎来重磅跨界新玩家——小红书开源了首个大模子dots.llm1。
dots.llm1是一个1420亿参数的MoE(羼杂群众)模子,仅激活140亿参数,可在中英文、数学、对皆等任务上兑现与阿里Qwen3-32B接近的性能。在汉文证据上,dots.llm1最终性能在C-Eval上达到92.2分,卓越了包括DeepSeek-V3在内的通盘模子。
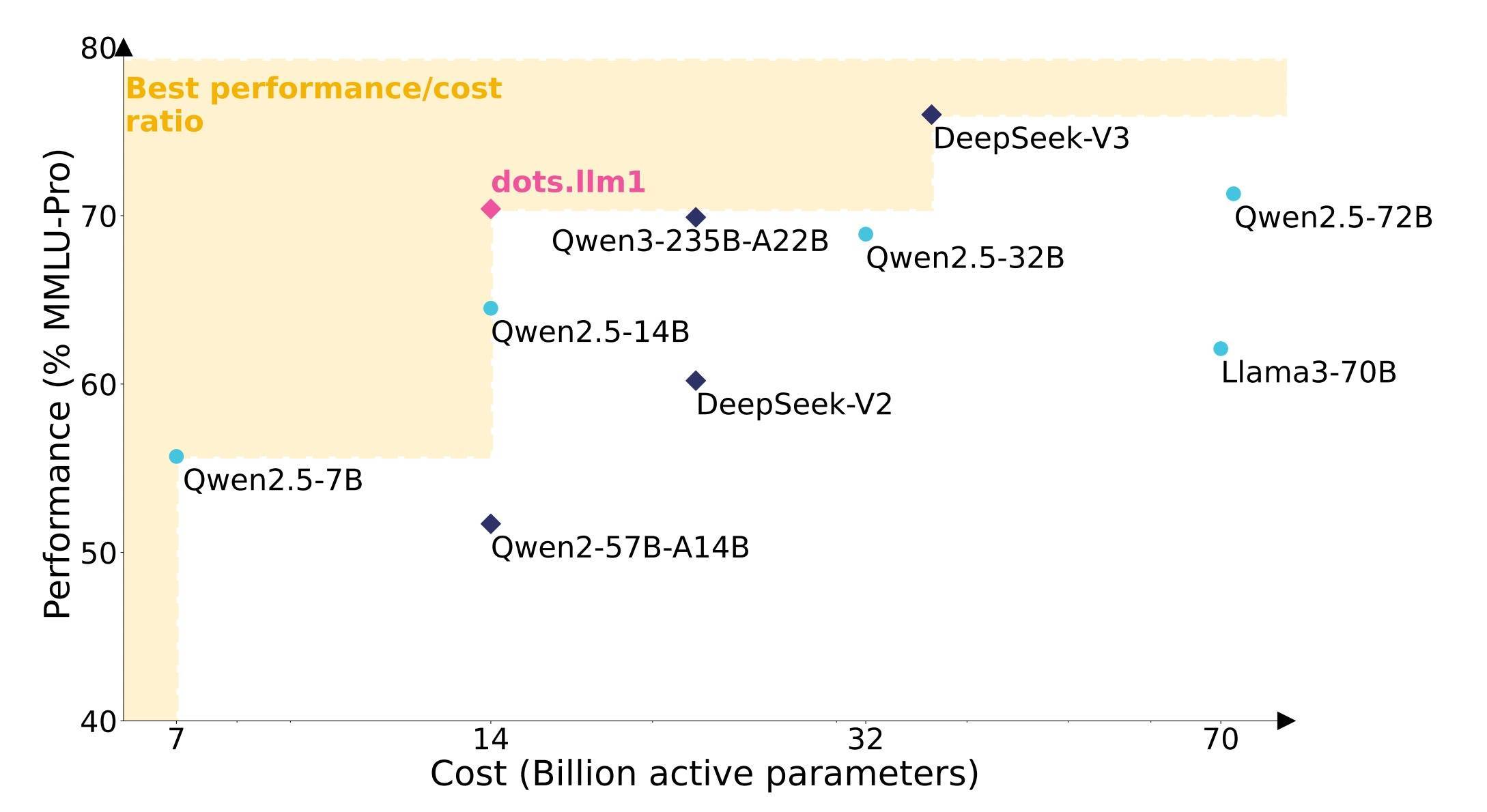
小红书开源大模子的一大特质在于数据。dots.llm1.ins在预磨砺阶段使用了11.2万亿的非合成数据。看成最新估值直飙2500亿元的国民级外交本体平台,小红书试图施展的是:通过高效的想象和高质地的数据,不错推宽阔型谈话模子的才气鸿沟。
凭证小红书hi lab团队(Humane Intelligence Lab,东谈主文智能施行室)公布的技能敷陈,其主要孝顺归来如下:
1、增强的数据处理:团队提议了一个可推广且细粒度的三阶段数据处理框架,旨在生成大领域、高质地和各样化的数据,以进行预磨砺。完满的过程是开源的,以此增强可复现性。
2、性能和老本效益:团队推出了dots.llm1开源模子,在推理过程中仅激活14B参数,同期提供全面且盘算推算高效的性能。dots.llm1使用团队的可推广数据处理框架生成的11.2万亿个高质地tokens进行磨砺,在各样任务中展示了宏大的性能,通盘这些都无需依赖合成数据或模子蒸馏即可兑现。
3、基础要领:团队引入了一种基于1F1B通谈变调和高效的分组GEMM兑现的革命MoE全对多通讯和盘算推算叠加配方,以普及盘算推算效能。
4、模子能源学的绽放可走访性:通过以开源体式发布中间磨砺查验点,团队的所在是使探讨界或者透明地了解磨砺过程,从而更深刻地了解大型模子的能源学,并促进LLM领域的加快革命。

Hugging Face地址:
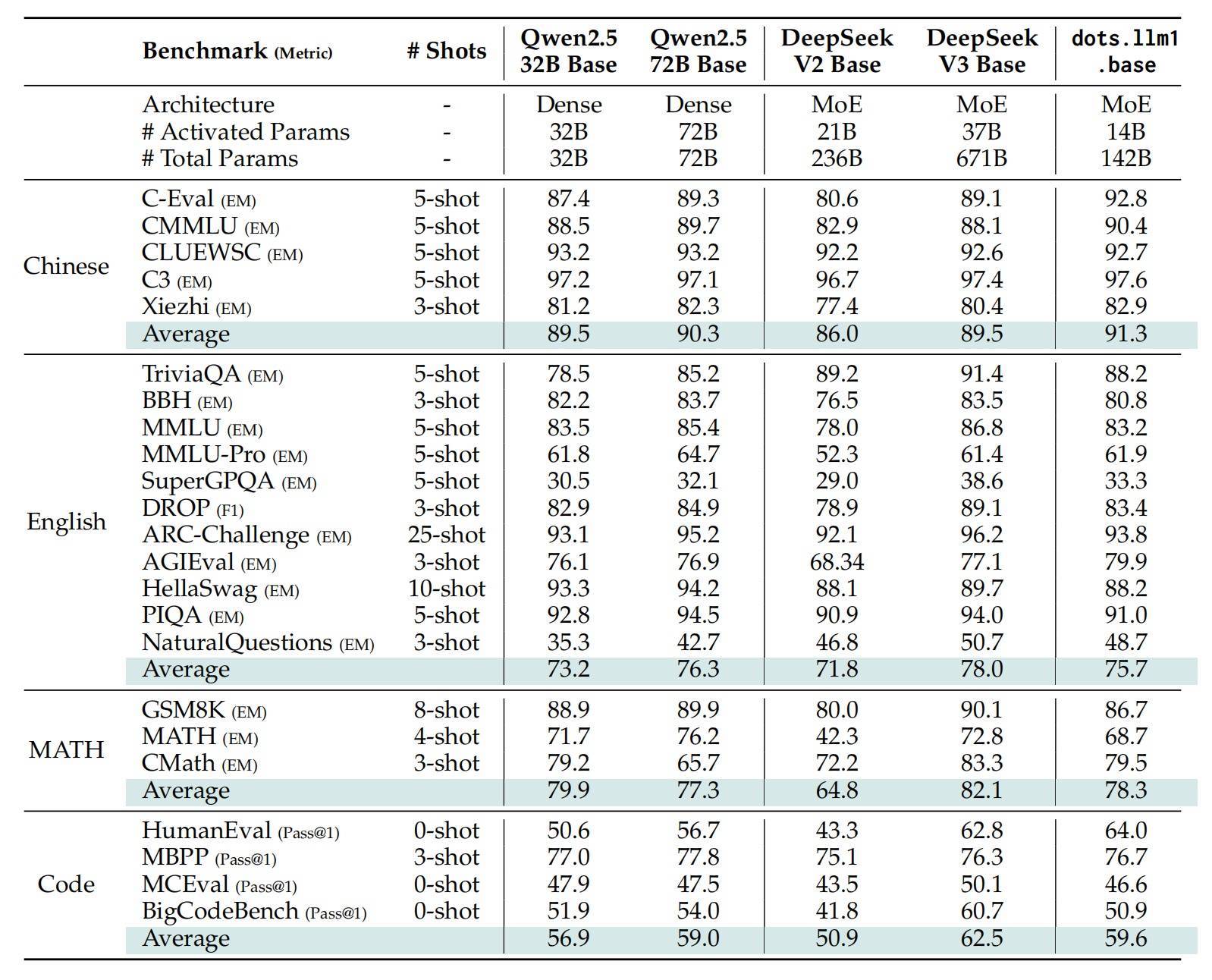
https://huggingface.co/rednote-hilabGitHub地址:https://github.com/rednote-hilab/dots.llm1一、性能打平Qwen2.5-72B,仅需激活14B参数起初看下dots.llm1的模子成果,团队磨砺得到的dots.llm1 base模子和instruct模子,均在轮廓主见上打平Qwen2.5-72B模子。
凭证评估收尾,dots.llm1.inst在中英文通用任务、数学推理、代码生成和对皆基准测试中证据较好,仅激活了14B参数,与Qwen2.5-32B-Instruct和Qwen2.5-72B-Struct比较成果更好。在双语任务、数学推理和对皆才气方面,dots.llm1.inst取得了与Qwen3-32B相配或更好的性能。
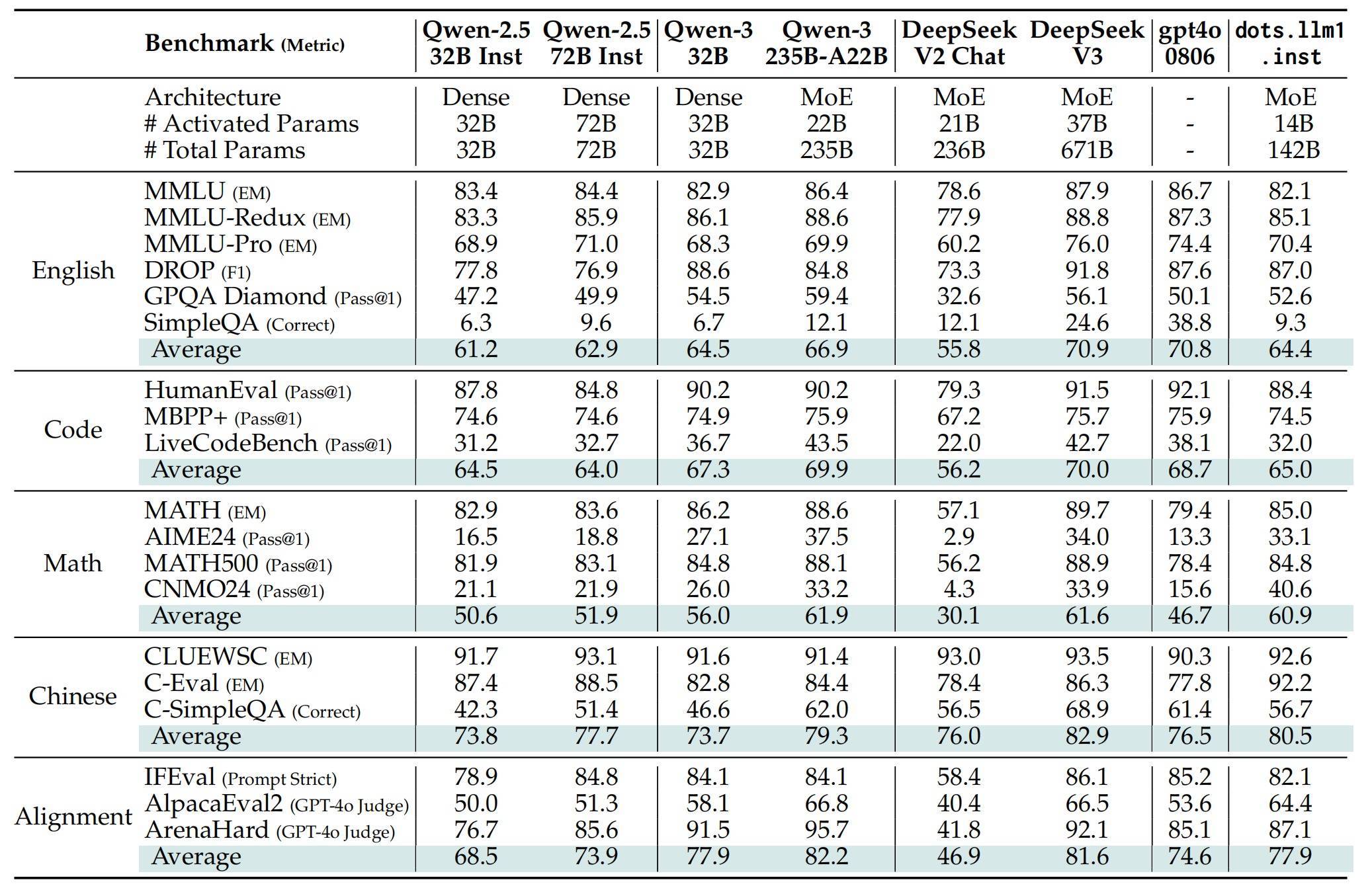
具体来看,在英语证据上,dots.llm1.inst在MMLU、MMLU-Redux、DROP和GPQA等问答任务中,与Qwen2.5/Qwen3系列模子比较具有竞争力。
在代码性能上,该模子与Qwen2.5系列比较不相高下,但与Qwen3和DeepSeek-V3等更先进的模子比较仍有差距。
在数学证据上,dots.llm1.inst在AIME24上获取了33.1分,突显了其在复杂数学方面的高档问题惩办才气;在MATH500的得分为84.8,优于Qwen2.5系列,并接近最先进的收尾。
在汉文证据上,dots.llm1.inst在CLUEWSC上获取了92.6分,与行业起初的汉文语义意会性能相匹配。在C-Eval上,它达到了92.2,卓越了包括DeepSeek-V3在内的通盘模子。
对皆性能方面,dots.llm1.inst在IFEval、AlpacaEval2和ArenaHard等基准测试中证据出有竞争力的性能。这些收尾标明,该模子不错准确地解释和实施复杂的请示,同期保持与东谈主类意图和价值不雅的一致性。
二、聘用MoE架构,11.2万亿非合成数据磨砺dots.llm1模子是一种仅限解码器的Transformer架构,其中每一层由一个正式力层和一个前馈集聚(FFN)构成。与Llama或Qwen等密集模子不同,FFN被群众羼杂(MoE)替代了。这种修改允许其在保持经济老本的同期磨砺功能宏大的模子。
在正式力层方面,团队在模子中使用了一种平时的多头正式力机制。在MoE层,团队降服DeepSeek、Qwen的作念法,用包含分享和颓败群众的MoE层替换了FFN,他们的实施包括为通盘token激活128个路由群众和2个分享群众,每个群众都使用SwiGLU激活兑现为细粒度的两层FFN。负载平衡方面,为了镌汰磨砺和推理时分的模子容量和盘算推算效能,团队罗致了一种与DeepSeek通常的补助无损的步调;此外,团队还罗致序列平衡亏欠,以退缩任何单个序列中的极点招架衡,以此使dots.llm1在通盘这个词磨砺过程中保持精良的负载平衡。
预磨砺数据方面,dots.llm1.ins在预磨砺阶段使用了11.2万亿tokens的非合成数据,主要来自通用爬虫和自有爬虫执取得到的Web数据。
在数据处理上,团队主要进行了文档准备、基于国法的处理和基于模子的处理。其汉文档准备侧重于预处理和组织原始数据;基于国法的处理旨在通过自动筛选和清算数据,最大适度地减少对多量东谈主工管制的需求;基于模子的处理进一步确保最终数据集既高质地又各样化。
其数据处理管谈有两项要道革命,如下所示:
1、Web参差消释模子:为了惩办样板本体和重复行等问题,团队开采了一种在坐褥线级别启动的轻量级模子。这种步调在清洁质地和盘算推算效能之间兑现了有用的平衡,代表了开源数据逼近不常见的私有功能。
2、类别平衡:团队磨砺一个200类分类器来平衡Web数据中的比例。这使其或者增多基于常识和事实的本体(举例百科全书要求和科普著作)的存在,同期减少假造和高度结构化的Web本体(包括科幻演义和居品面貌)的份额。
经过上述处理经由,团队得到一份高质地的预磨砺数据,并经过东谈主工校验和施行考证,施展该数据质地显赫优于开源Txt360数据。
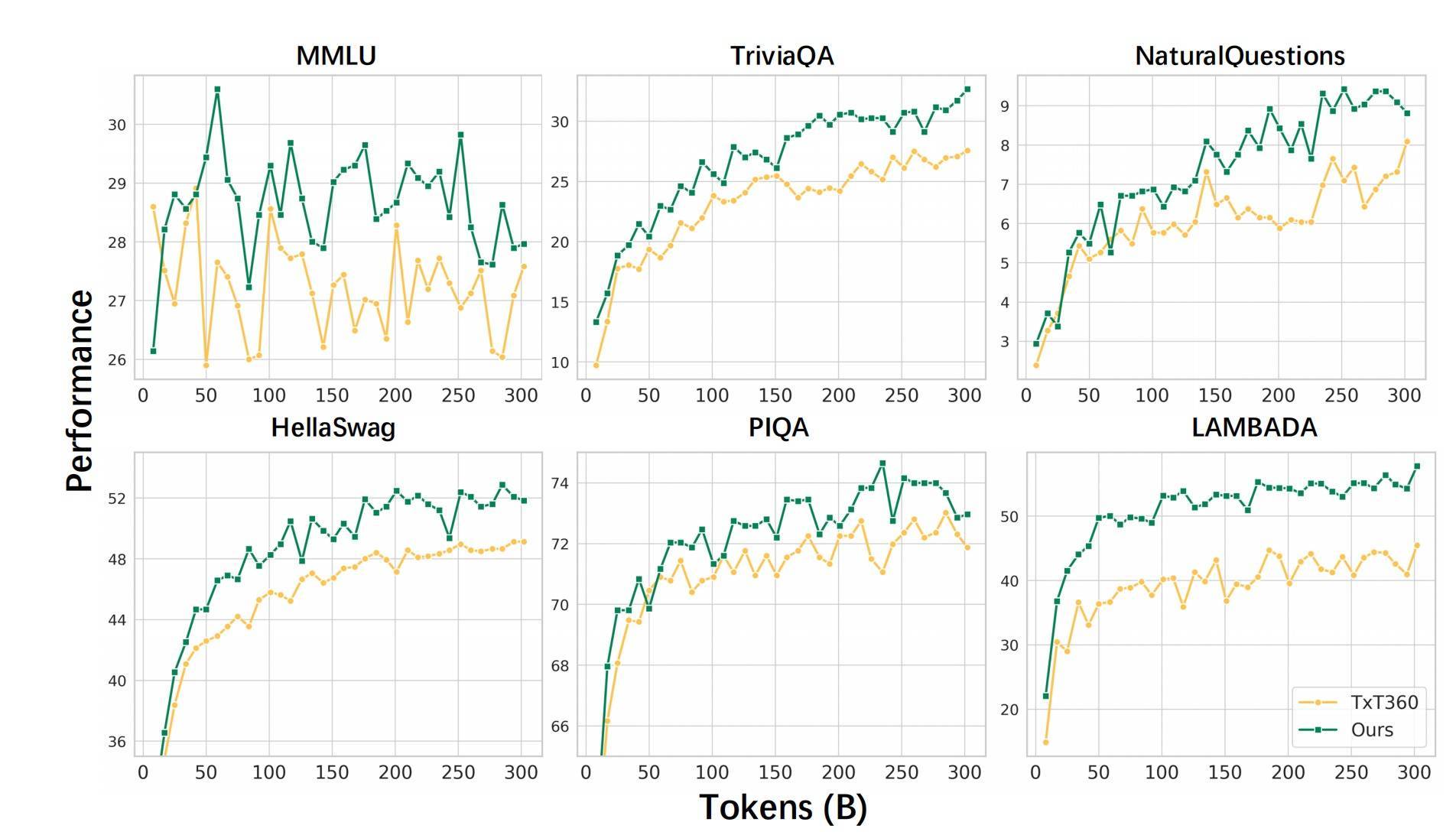
在参数方面,dots.llm1模子使用AdamW优化器进行磨砺,模子包含62层,第一层使用平时密集FFN,后续层使用MoE。
团队在预磨砺时分将最大序列长度建立为8k,并在11.2T tokens上磨砺dots.llm1。在主要磨砺阶段之后,该过程包括两个退火阶段,所有包含1.2万亿个数据tokens。
紧接着,团队在退火阶段之后兑现高下文长度推广。在这个阶段,他们在使用UtK计谋对128B记号进行磨砺时保持恒定的学习率,将序列长度推广到32k。UtK不是修改数据集,而是尝试将磨砺文档分块成更小的片断,然后磨砺模子以从连忙分块中重建有计划片断。通过学习解开这些打结的块,该模子不错有用地处理较长的输入序列,同期保持其在短高下文任务上的性能。
在预磨砺完成后,为了全面评估dots.llm1模子,团队将该模子在汉文和英文上进行了预磨砺,团队评估了它在每种谈话中卓越多个领域的一套基准测试中的性能。如下图所示,与DeepSeek-V2比较,惟有14B激活参数的dots.llm1性能更佳,后者与Qwen2.5-72B水平相配。
dots.llm1在大多数域中证据出与Qwen2.5-72B相配的性能:1、在谈话理罢黜务上,dots.llm1在汉文意会基准测试中取得了较高性能,主要收获于数据处理管谈。2、在常识任务中,诚然dots.llm1在英语常识基准上的得分略低,但它在汉文常识任务上的证据仍然矜重。3、在代码和数学领域,dots.llm1在HumanEval和CMath上获取了更高的分数。深嗜深嗜的是,在数学方面,咱们不雅察到dots.llm1在零样本建立下的性能比少数样本建立要好,普及了4个百分点以上。
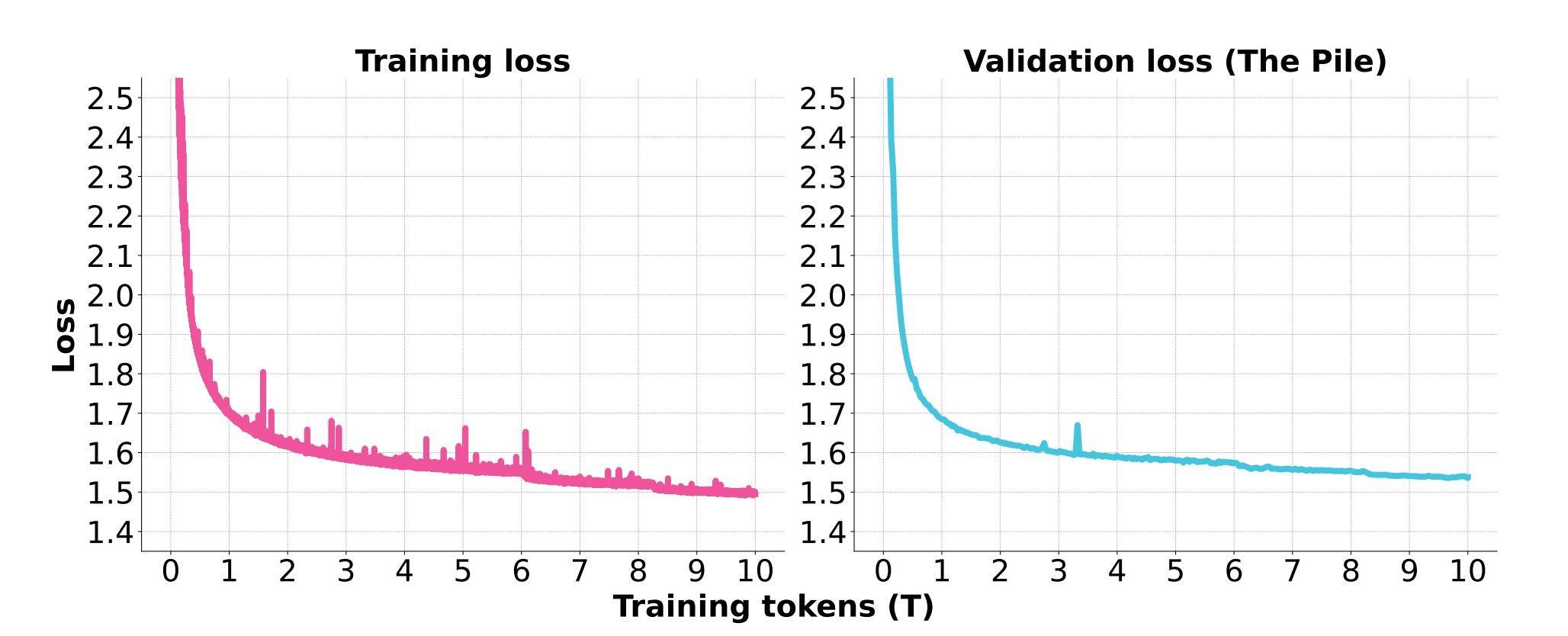
以下亏欠弧线杰出了磨砺过程的一致踏实性。在6万亿个磨砺token中,团队将批处理大小从6400万个治愈为9600万个,从8.3万亿次增多到1.28亿次。在通盘这个词磨砺时分,莫得出现无法还原的亏欠峰值事件,也不需要回滚。
在预磨砺及评估后,团队在后磨砺阶段对模子进行了监督微调。
在数据羼杂方面,其基于开源数据和里面谛视数据集聚了约莫400k个请示调优实例,主要逼近在几个要道领域:多谈话(主如果汉文和英文)多轮对话、常识意会和问答、复杂的请示跟班以及触及数学和编码的推理任务。
在微调竖立方面,dots.llm1.inst的微调过程包括两个阶段。在第一阶段,团队对400k请示调优实例实施上采样和多会话聚拢,然后对dots.llm1.inst进行2个epoch的微调。在第二阶段,其通过辩认采样微调(RFT)进一步增强模子在特定领域(如数学和编码)的才气,并勾搭考证器系统来普及这些专科领域的性能。
结语:用高质地数据推宽阔模子鸿沟不错看到,dots.llm1定位是一种经济高效的群众羼杂模子,“以小博大”。通过仅激活每个记号的参数子集,dots.llm1镌汰磨砺老本,试图提供了与更大的模子相配的收尾。
比较于同业火星电竞,小红书觉得我方的一大上风是数据处理管谈,可助其生成高质地的磨砺数据。Dots.llm1施展了高效的想象和高质地的数据不错贬抑推宽阔型谈话模子的才气鸿沟。